 Rogério Chaves
Rogério Chaves
Is Neymar Better Than Average?
I’ve been reading the book Doing Bayesian Data Analysis, and there is an example there with baseball, which I’d like to try for football.
Basically, we want to estimate what’s the probability of a player scoring in a match, and which part of that probability is influenced by their position on the field vs other factors. We’ll focus on Neymar but I’m actually using the data of all players from UEFA Champions League.
First let’s load our data. I collected data from UEFA Champions League for 2018 and 2019–2020, each row is a participation of a player in a match, with which position they were on this match, and how much goals they scored. Players that were in substitution bench during the match but never entered the field are not included
1 | import pandas as pd |
Let’s take a look on matches that Neymar participated
1 | df[df['player'] == 'Neymar'] |
Just to help us understand our data a bit, what’s the distribution of goals per match?
1 | df['goals'].hist(); |
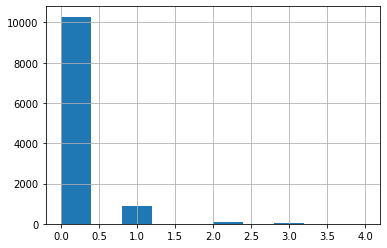
Woah a Poisson distribution as expected, I love those. Okay and which positions score more?
1 | df[['position', 'goals']].groupby('position').sum() |
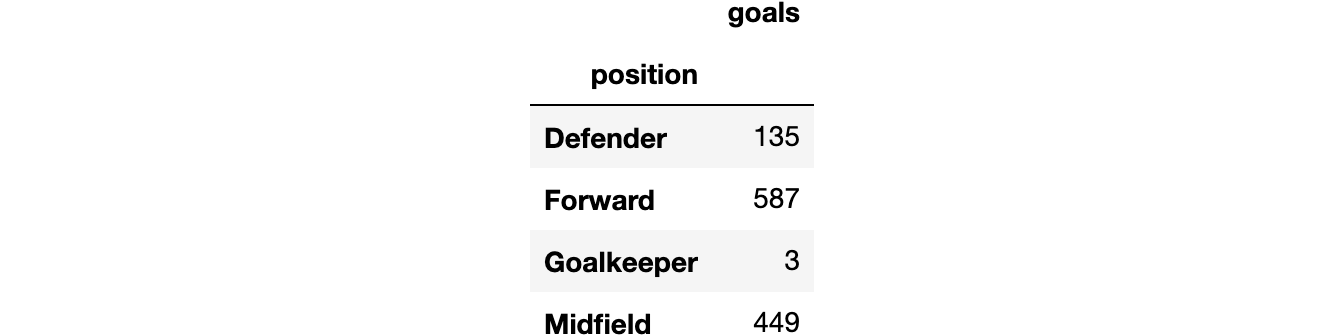
Alright zero surprises so far. Let’s move on and build a Logistic Regression model, which will give us a probability of a goal given a player and their position.
1 | from sklearn.linear_model import LogisticRegression |
1 | 0.9107711354793067 |
Logistic regression can fit our data with 91% accuracy, seems pretty good. Now let’s take a look on what’s the probability of Neymar scoring a goal in some future match:
1 | neymar_id = 276 |
1 | 0.3835193670312905 |
38%, not bad, what if Neymar were a Midfield player instead of Forward?
1 | X_example = one_hot_encoder.transform([[ neymar_id, "Midfield" ]]) |
1 | 0.2424111808266389 |
24%, is it good? Is it above average? I think so, but let’s check what’s the average of player in this positions scoring at all. For that we will take the average of probabilities of all players in that position
1 | def prob_for_position(position): |
1 | Forward position mean 0.165252941308293 |
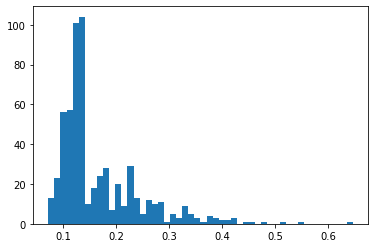
1 | Midfield position mean 0.08585727912713484 |
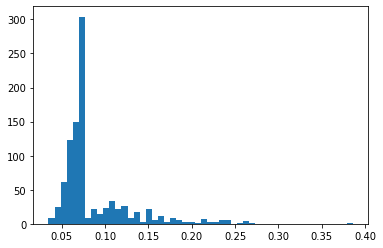
It’s interesting to notice that the histograms above remember somewhat a beta distribution, closer to the left side, never smaller than zero, this will be important for us later
But answering our question, yes, Neymar is way above average, as an average forward would score with 16.5% chance while Neymar gets 38% on forward position. It seems that being Neymar puts a hell lot of weight in the probability to score in a match.
Remember: this doesn’t really mean that Neymar the person alone is way better than everybody else, because many other variables such as “Playing in PSG with good team members” are agregated in “being Neymar”, as it’s not really possible for us to deconfound this variable right now. On the other hand the position variable (forward, midfield) is pretty deconfounded as we measure across all players
So what would be the probability of Neymar scoring, regardless of position?
1 | def prob_for_player_id(player_id):\ |
1 | 0.18960539993655143 |
What about Messi?
1 | messi_id = 154 |
1 | 0.21051765637224326 |
Seems like Messi has a bit higher probability of scoring than Neymar, 21% vs 19%
Those are nice point estimations, but you shouldn’t take them as absolute truth, because our data is just a small sample from all matches by those two players (only 2 UEFA championships), as our input is incomplete, how much can we really trust the data we collected?
One alternative approach that helps us with that is building a Bayesian model, where we can estimate distributions over our parameters, as you will see next
Measuring uncertainty with Bayesian Analysis
For this next part I’ll use R with rjags because that’s what I learned from the book. I even tried to do the same with PyMC3 but no success so far.
Anyway, first, let’s load and transform the data just like we did on previous python notebook
1 | require(rjags) |
Let’s just setup some variable we will need to build our model: y, which means weather there was a goal or not, positions and playerIds
1 | y = apply(df['goals'], 1, function(x) if (x > 0) { 1 } else { 0 }) |
Now the most exciting part, let’s build our hierarchical model!
1 | modelString = " |
Then compile it
1 | writeLines(modelString, con="TEMPmodel.txt") |
So, let me try to explain everything. First of all, our goal is to model the probability of a goal happening or not in a match, so this is clearly a bernoulli trial, which is about true/false results, this is defined by the y[i] ~ dbern part. The argument inside dbern is the probability for the given player, but how do we define that?
Player probability of scoring is a beta distribution, as we saw on the previous python notebook. We want to find the probability of scoring for each player, for example, a player with a 0.5 mean probability would probably score every other match. A beta distribution is defined by parameters alpha and beta, but because those are very hard to intuitively interpret, I used a formula to be able to define it based on mean and variance. But who defines this mean and variance then?
The player position! Each position (Forward, Midfield, Defender, Goalkeeper) will have a mean probability of goal that fits for all players, simply defined here by a uninformative uniform distribution between 0 and 1. So the players influence the mean position probability, and the position in turn affects individual players probability to score. This is the magic of Bayes hierarchical models!
1 | update(jagsModel, n.iter=500) # burn-in |
Alright, so finally, let’s plot our posteriors and start asking questions! What’s the mean probability of a forward player to score in a match?
1 | mcmcMat = as.matrix(codaSamples) |
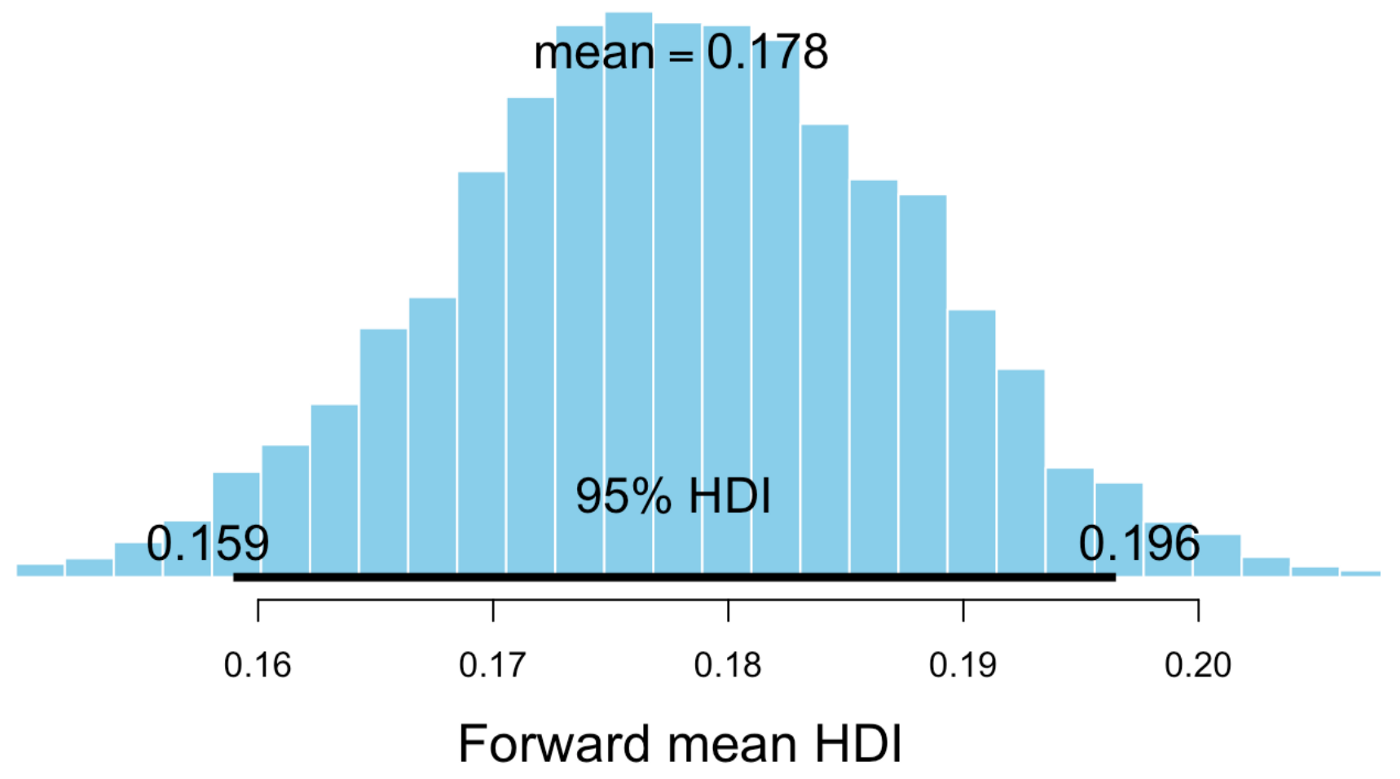
Between 0.159 and 0.196. Here you see a cool advantage of using Bayesian methods: it’s common to look at distributions rather than point estimates, so we can have an idea of our uncertainty. What about Neymar, is he in this range? Or is he conclusively better than average?
1 | neymarId = 276 |
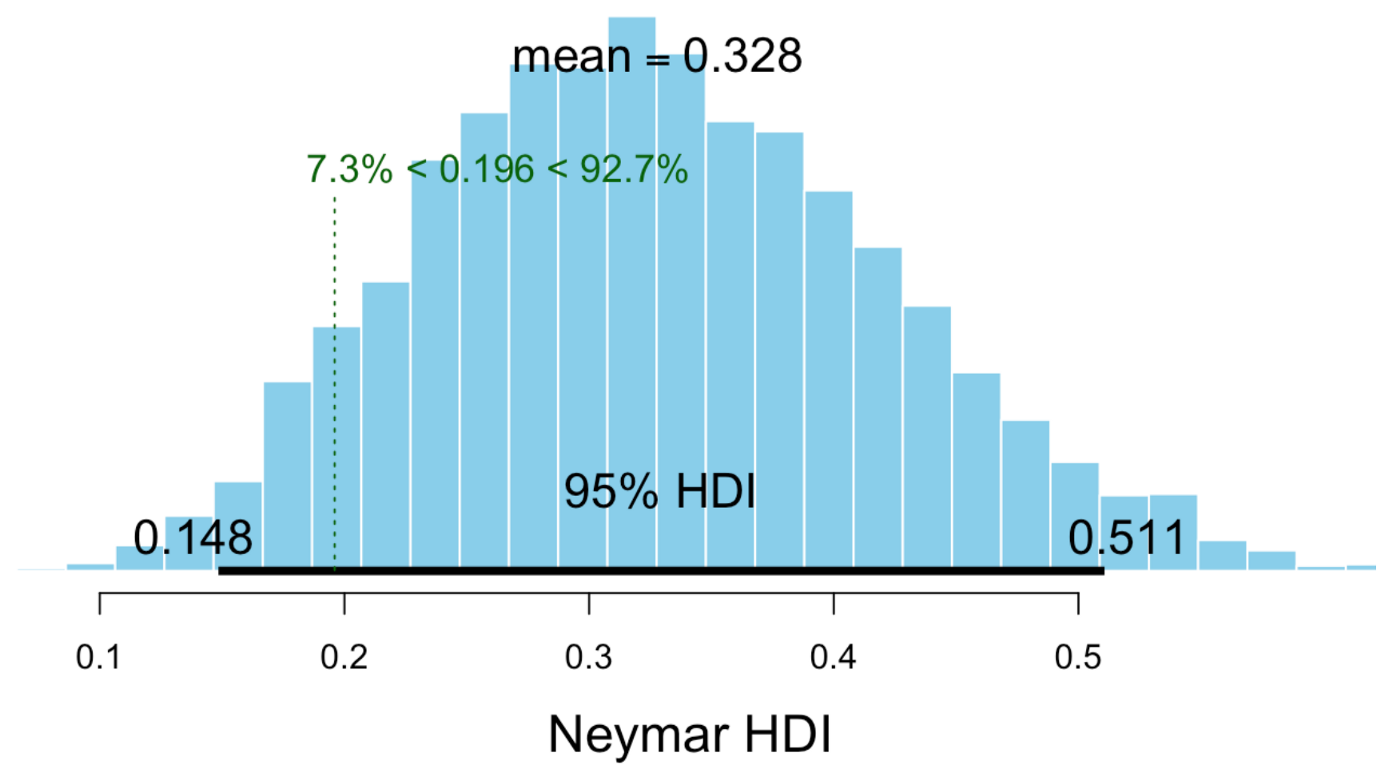
Well the mean is similar to what we got using Logistic Regression, 0.38 vs 0.328 here. But is he conclusively better than average? Almost but no!* The lower bound for Neymar is 0.148, which is inside the average range, so it seems like he is probably better, but variance is quite high, maybe it was just luck all this time? What about Messi?
- considering 95% HDI
1 | messiId = 154 |
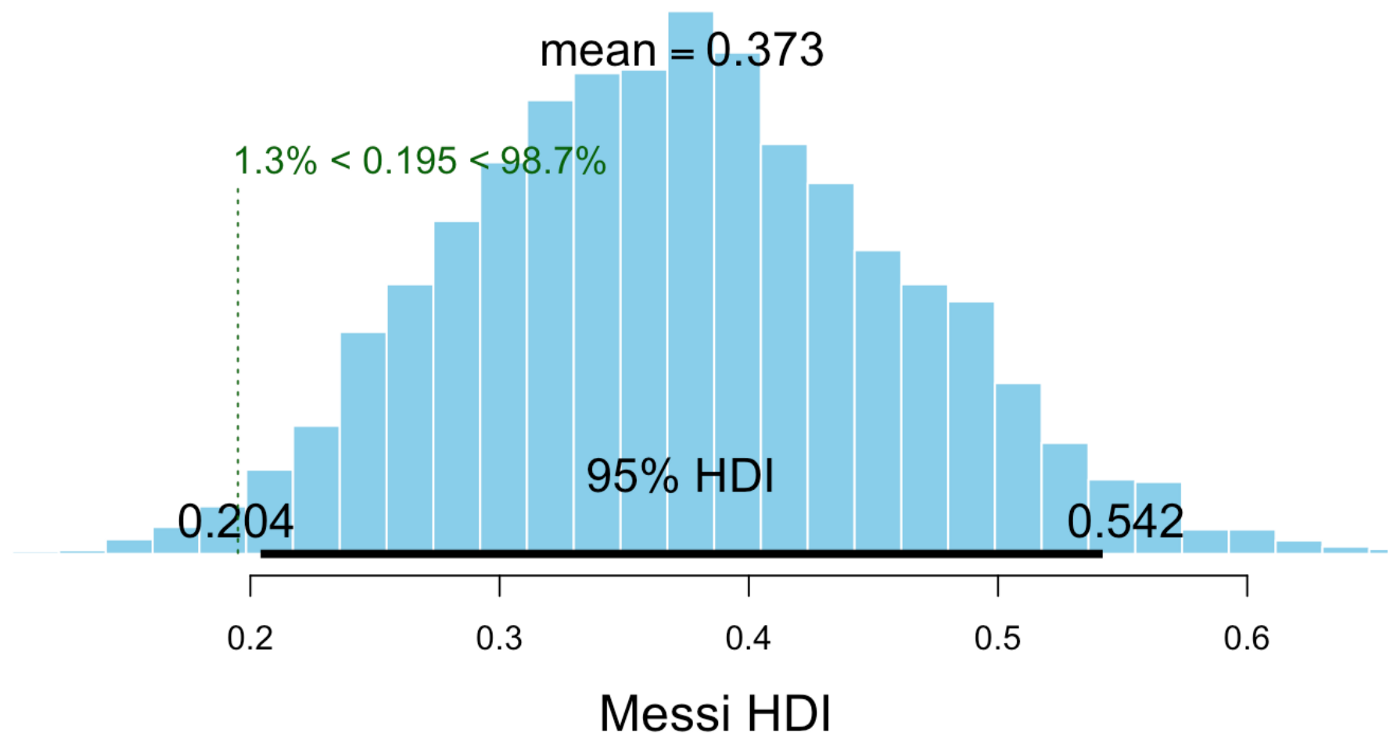
Yes! Messi lower bound is 0.204, considering 95% Highest Density Interval he is conclusively better than average forward position players! It does not overlap with the upper bound of 0.196 for average forward players.
That was it, just a small bayesian exercise, I hope it was as fun to you as it was for me.
Disclaimer: I’m not an expert so I may not be interpreting this results correctly, please let me know if I don’t.
If you also want to play with it, you can find the dataset and the notebooks on my github.
Thanks for reading!
Comments
If you’d like to add a comment, please send a merge request adding your comment here, copying this block as an example